
Deep Learning in Real-time Rendering Pipelines


In this blog post I will give an overview of the applications of Machine Learning (ML) in the domain of real-time computer graphics and why it matters. We will take a look at some fundamental problems in modern real-time rendering and possible ML-based solutions.
Real-time Rendering - A Short Recap
The history of computer graphics is quite interesting. GPUs transitioned from being highly specialized tools used to visualize shiny pixels to massively parallel general purpose data crunchers. We started out creating very simple images with oscilloscopes in the 1950s and ended up rendering very complex scenes with high-quality ray-traced lighting in real-time in the 2020s. A time span of ~70 years!
In the process, we democratized massively parallel processors in the form of consumer GPUs. Today everyone interested in gaming has their own small-scale computer science lab right at their fingertips. This not only led to fascinating use-cases in gaming but also had a significant cross-pollination effect in other data-heavy areas such as Machine Learning. Yup, by demanding shinier and shinier pixels we eventually kick-started the deep learning revolution (let's pretend that's the only reason...). We did it gamers!


But why does this matter for computer graphics? Real-time rendering is inherently a problem solved by massive parallelization! Given a description of a scene we want to calculate an image from a given camera perspective. Objects in the scene are described as a list of vertices representing the object's surface ("mesh"). Every single vertex contains attributes required to render the mesh appropriately, e.g. the position, normals, colors, texture coordinates, etc. We then pass these vertices to the GPU where a render pipeline processes the data.

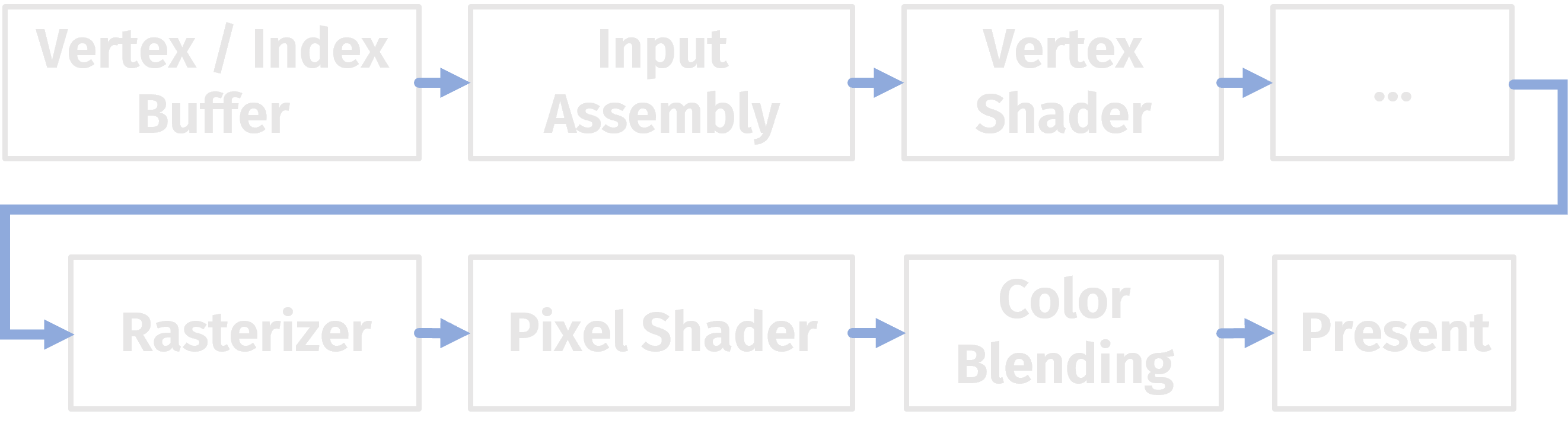
The render pipeline creates primitives (e.g. triangles) from the provided Vertex and Index Buffers. We typically then process the vertices in some way in the vertex shader, rasterize the primitives, and finally we process potential pixels in the pixel shader. Once we went through all of the stages we see beautiful pixels on our screen (Well... Actually it's a little bit more complicated and we merely scratched the surface. But there are plenty of free resources available if you want to dive deeper).
All of this has to happen for every single vertex and fragment (potential pixel) in the scene in real-time, i.e. targeting around 60 Hz minimum. That means to render a single frame we should stick to a time budget of only 16.67 milliseconds which of course also has to include the update of the underlying simulations and game systems. Luckily, for a lot of the data the applied operations stay the same. Often the only thing that changes is the underlying parameterization. The perfect situation to parallelize the workload - exactly what our GPU is good at! Great, real-time rendering is solved... Or is it?
Modern Problems Require Modern Solutions
While it's true that clever parallelization carried us a long way it's not the ultimate solution to all of our problems. After all we are still gamers. We not only need beautiful pixels, we also need more of them! There's never enough.

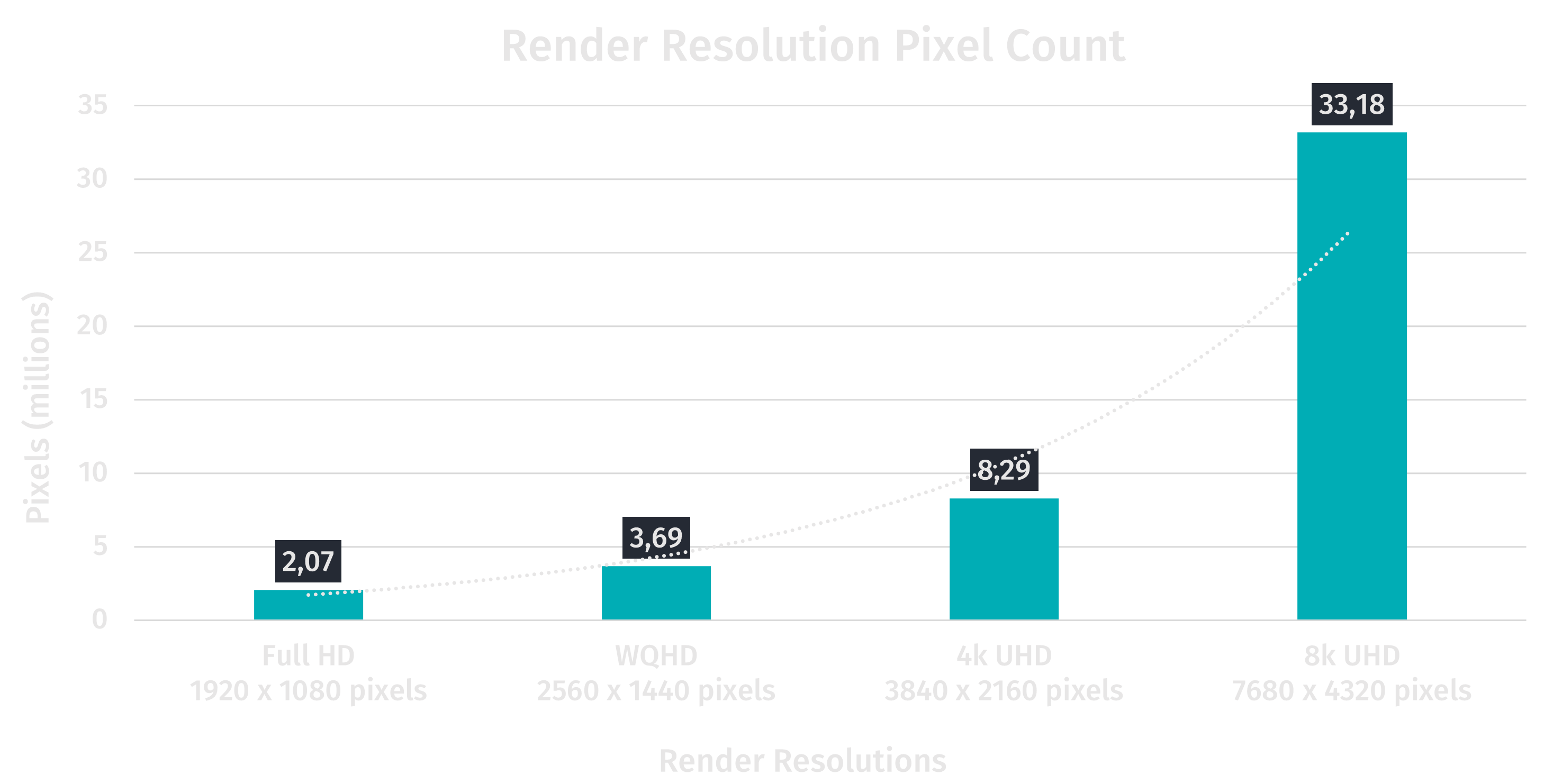
Back in the days when the most common resolution was 1080p our GPU only had to fill about 1920 * 1080 = 2.073.600 pixels per frame. Nowadays monitors with 4k resolution (3840 * 2160 = 8.294.400 pixels) become more and more common in gaming setups and 8k monitors (7680 * 4320 = 33.177.600 pixels) are right around the corner. With ever-increasing rendering resolutions expensive per-pixel calculations eventually slow the graphics pipeline down to a crawl.
Real-time ray tracing is one of the most prominent examples which adds noticeably to the render quality but also suffers from very high render resolutions. The theory behind ray tracing is very simple: For each pixel on the screen light rays are cast into the scene. The light rays collide with and bounce off of surfaces in the scene. Each collision absorbs some of the light depending on the surface material which in turn affects the final color of the ray. The direction in which light rays bounce off is determined by sampling from a Bidirectional Reflectance Distribution Function (BRDF) which considers the direction of the light ray, surface properties and material attributes, such as the surface's roughness. Due to this stochastic nature of ray tracing it isn't enough to calculate only one single sample per pixel (spp) as it would just result in a very dark, noisy and aliased image. Instead, in order to achieve good image quality we have to accumulate multiple spp.


Simulating a ton of light rays is computationally expensive and for a very long time this technique was only viable for offline rendering. Nowadays we have dedicated hardware accelerating computations enough to make ray tracing real-time-viable but even then the ray budget is very limited - especially at high resolutions. In turn, we are forced to undersample aggressively.
As you can see, it is highly desirable to cut down on the amount of pixels we have to calculate. Of course the straight forward solution to this problem is to simply render our image at low resolutions and then apply upsampling to show the image at the target resolution. In modern games this approach is often exposed as setting for users with weak hardware. The upsampling is typically achieved with "traditional" filters (e.g. bilinear upsampling) or more sophisticated techniques such as checkerboard rendering which results in noticeable drop in image quality. No good, but the idea is great.
So the question is: How can we do this while still maintaining the image quality we expect when rendering at native resolutions? Well, luckily learning filters is exactly the thing convolutional neural networks (CNNs) excel at! ML to the rescue!
Denoising, Anti-Aliasing and Upsampling
Quality enhancement or intelligent upsampling of images is a very prominent use-case of deep learning. The basic idea is very simple: A neural network is trained to solve an image reconstruction task, e.g. given a "flawed" image as input produce a "fixed" image as output. Of course this is just a very rough overview, but you get the idea. If you want to dive deeper I recommend checking out some popular papers on image super resolution (e.g. SRGAN or SRCNN) or neural denoising (e.g. Neural Denoising with Layer Embeddings).
This exact same ML-based approach can be applied to minimize computational costs in computer graphics. Our renderer produces noisy images at low resolutions, we hand them over to a machine learning model trained on denoising and image upsampling, let it do its magic and we expect flawless images similar to renderings at native resolutions. Ez pz, lemon squeezy. The tricky part is making this run in real-time and as part of the rendering pipeline.
ML-augmented Rendering Pipeline
Traditional real-time rendering pipelines usually follow a similar data flow. We can dissect the real-time rendering process into several phases:
- First we render the "raw" scene and auxiliary buffers, e.g. scene depth, motion vectors, etc
- Then we apply some kind of anti-aliasing technique, e.g. Temporal Anti-Aliasing (TAA)
- We finalize the scene rendering in some kind of post-processing stage, e.g. apply tone mapping
- Finally we render the UI on top and show the image
Our image enhancement model (e.g. a neural denoiser) fits right between the scene rendering and the post processing stage, replacing TAA. We take the low resolution, noisy and aliased rendering output, process it with the model and receive a denoised and anti-aliased rendering of the scene. We then pass the high quality image to the engine's post-processing stage. After post-processing, we apply neural upsampling to reach the target resolution.
Model Architecture
How exactly the NN architectures of the available commercial solutions look like is of course a well-kept secret. We have to rely on sparse information, educated guesses and extrapolation. From GDC presentations (e.g. Truly Next-Gen: Adding Deep Learning to Games & Graphics), research papers (e.g. Temporally Stable Real-Time Joint Neural Denoising and Supersampling), and technology deep dives (e.g. Intel XeSS Technology Deep Dive) we know that it's all about temporally stable convolutional autoencoders.

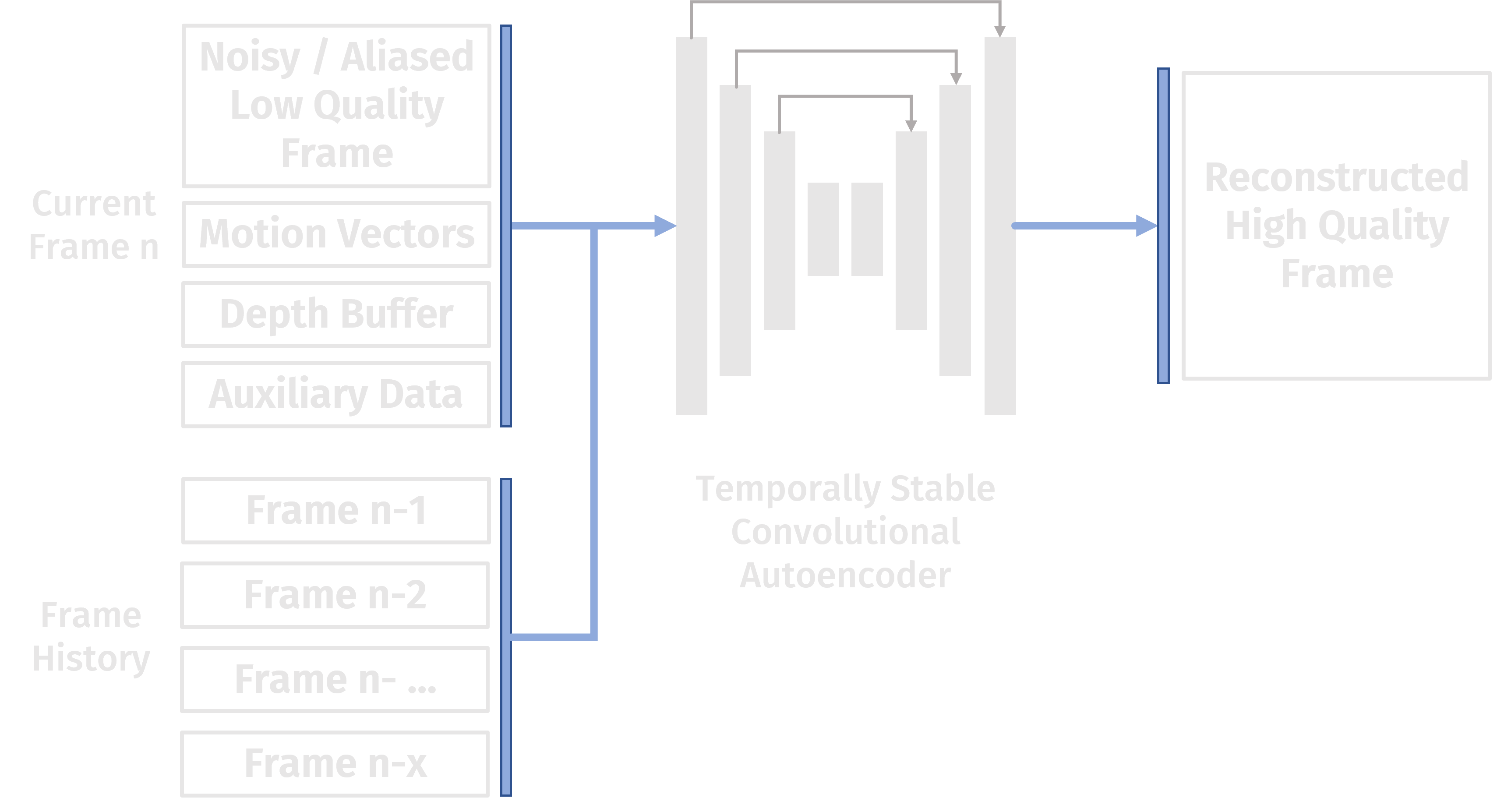
The encoder takes the current 1spp renderer output (color + motion vectors + auxiliary buffers) and concatenates the data with previously processed frames taken out of a frame history buffer. The data is then passed into a sequence of convolution layers, forcing the NN to learn increasingly higher level features with increasing network depth. Eventually a bottleneck is reached which contains a latent feature vector.
The decoder learns how to make sense of the high level features contained in the latent vector to generate the desired target output. It takes the bottleneck's latent vector and passes it to a sequence of expanding transposed convolution layers until eventually the original input size is reached in the output layer. The ground truth data is simply a very high quality rendering of the scene, e.g. a 64 spp RGB image.
The neural network is trained with some kind of perceptual loss. Perceptual losses measure the perceived differences between the inferred output and the ground truth. Traditional image super resolution networks often use a VGG-based perceptual loss but my guess is that this didn't work out for real-time rendering as we deal with an entirely different domain. While real-time rendering tries to approach photorealism it's just not quite there yet. Also there's always some kind of artistic freedom which just can't be captured in photography datasets. Instead, the loss function is a custom perceptual loss based on a NN trained specifically on real-time rendering footage, e.g. with an object segmentation task.
Also, I'm somewhat confident that the NNs make use of skip connections in order to pass features from encoder to decoder layers as this is a common approach in image super resolution (and it was indicated on some presentation slides) but besides that we can only guess which additional layers are used and how all the layers are configured.
Model Training - "Puppies In Puppies Out"
For model training we have to collect a dataset which consists of two parts: We require the low quality input data and the exactly fitting high quality ground truth data. Both input and ground truth consist of the raw color output plus matching auxiliary buffers. Of course the ground truth data has to be of flawless render quality, i.e. it has to be without any artifacts and it should crank the graphical fidelity slider to 11 trying to approach the quality of offline renderers. This includes maximum shadow quality, full path tracing and whatever other feature we want to cover. Collecting perfect training data is absolutely crucial as the NNs will learn to reproduce every single flaw encountered in our data set - Puppies in, puppies out!
But high quality training data alone is not enough! We also have to ensure proper domain coverage in order to train a robust model. What these domains looks like obviously depends on the application we train our model for. Think of all the different levels, landscapes, weather effects, lighting conditions, indoor scenes, outdoor scenes, objects and materials the model will encounter during inference. It's not trivial.
Chances are that we have to collect all of this data multiple times, e.g. at different quality settings and resolutions. But it's not quite enough to just render the same scenes again and again, it also has to be frame perfect! Therefore we have to prepare the rendering engine so we can reliably capture the required data:
- Rendering has to be deterministic (which may be especially tricky in combination with temporal effects like screen space jitters!)
- Access and export of all the required data (rendered scene and auxiliary buffers) has to be super fast and easy
- Double check for correct motion vectors! According to NVIDIA these seem to be a common source for bugs.
- Temporally accumulated per-pixel operations may result in artifacts, e.g. dithering effects.
We may also further extend the data set with common data augmentation techniques such as rotations, flips, salt & pepper noise, pixelation or channel randomization. However we have to be careful as data augmentation increases the input space which in turn may hinder the NN's learning process due to possible "fake" data that will never be encountered during inference. Always prefer to capture more data than to augment existing datasets if possible.
Implementation - Gotta Go Fast!
Optimizing the runtime of NNs is a complex topic and way out of the scope of this blog post. I'll leave it at a quick overview of the development process described by NVIDIA in their GDC presentation: At NVIDIA, the development of NNs used in real-time rendering pipeline is usually split into two phases: An experimentation phase and an optimization phase. During the experimentation phase their goal is to iterate quickly and eventually develop a proof of concept which reaches acceptable quality during inference. Inference timings may be neglected and they rely on common tools of the trade such as PyTorch, TensorFlow and Keras to build and train NNs.
Once they found a promising approach, they optimize for real-time inference. Their goal is to speed up the NNs enough to make them run in noticeably less time than the traditional render pipeline while producing output of similar visual quality. To reach the required speed it's recommended to implement models with specialized low-level APIs such as DirectML. CUDA and cuDNN are also a totally valid option but NVIDIA mentioned that they didn't manage to reach the same speedup as with DirectML.
Are We There Yet?
ML-augmented rendering pipelines are already in use today. For example, a lot of AAA games give users the option to toggle on DLSS - and frankly it's often quite necessary in order to achieve real-time performance in heavy scenes with maxed out graphic settings.
But is it perfect? I don't think so:
- Temporal accumulation of scene data results in ghosting artifacts
- Previously occluded objects are hard to upscale due to lacking data in the frame history.
- At the time of writing this blog post generalization of the models was problematic. For example, DLSS was not available out of the box for every application. I think a fine-tuned model had to be trained for specific applications and domains. This may have changed with recent versions of DLSS.
Potential Future Directions
In order to lower the entry barrier into ML research and to tackle the generalization and robustness issues, it may be beneficial to invest resources into building a big, open source dataset of real-time computer graphics data to train models on. As of the time of writing such a data set is not available (at least I haven't found one).
Further, the usage of NNs is currently mostly limited to the "raw" rendering phase of scenes. What if we extend the usage of ML to the render pipeline's post-processing stage? In the future, we could possibly provide pre-trained networks for effects such as high-quality anti-aliasing, depth of field and plausible motion blur.
Conclusion
In this blog post I gave a rough overview of problems in real-time computer graphics and how to solve them with ML-based techniques. We learned that modern real-time computer graphics suffer from computationally expensive techniques such as ray tracing which don't scale well with increasing render resolutions. NNs are a possible solution to this problem as they perform well in image reconstruction tasks such as image super-resolution and image denoising. We can use this to our advantage and augment our real-time rendering pipeline with well-placed runtime-optimized neural upsamplers and neural denoisers.
The NNs themselves are typically fully convolution encoder-decoder networks, taking noisy low resolution images as input and producing denoised high-quality images as output. Training datasets therefore have to consist of frame-perfect renderings of both low render quality and very high render quality, cover all the desired lighting conditions and render domains. To train the NNs, a domain-specific perceptual loss is used. Preparing a deterministic renderer for the proper collection of this training data may be a complex and time-consuming task due to temporal effects, such as jittering. For the implementation, it's recommeded to first build a working prototype with common tools such as PyTorch and TensorFlow and then optimize for production with frameworks such as DirectML.
ML in the render pipeline brings its own set of problems, such as ghosting artifacts due to missing data in the frame history and lack of generalization due to the multitude of domains in real-time rendering.
In the future ML could be potentially used in the post-processing stages of the real-time rendering pipeline, such as high-quality anti-aliasing, depth of field or motion blur calculations.
Resources and Further Readings
Here are the resources I found while digging deeper into the topics I discussed in the blog post.
Related Papers
- Temporally Stable Real-Time Joint Neural Denoising and Supersampling
- Deep Learning Techniques for Super-Resolution in Video Games
- Perceptive Loss: HFENN
- Perceptual Losses for Real-Time Style Transfer and Super-Resolution
- Neural Temporal Adaptive Sampling and Denoising
- Neural Network Ambient Occlusion
- Neural Supersampling for Real-time Rendering
- Noise2Noise
Talks & Presentations
- Slides: Image Reconstruction for Real-time Rendering with Deep Learning
- Truly Next Gen (GDC)
- Real-Time Inference: Considerations for Achieving Best Performance in Applications and Games
- Optimizing TensorRt Conversion for Real-Time Inference On Autonomous Vehicles
- Intel XeSS Technology Deep Dive